One of the most important things to understand when working with reactive streams is that things happen in different moments. In the following, we describe this play in three different acts: assemble, subscription, and data flow
To start, let’s considerer the following code excerpt, which uses Project Reactor’s reactive streams implementation.
@Test
fun `a play in multiple acts`() {
val done = CountDownLatch(2)
log.info("Creating the mono, i.e., the processing pipeline")
val mono: Mono<Int> = Mono.create<Int> {
log.info("Mono.create callback called, emitting value")
it.success(42)
}
.map {
log.info("map: multiplying value by 2")
it * 2
}
.delayElement(Duration.ofMillis(1000))
.map {
log.info("map: dividing value by 2")
it / 2
}
log.info("Mono created, resting for a bit...")
Thread.sleep(1000)
log.info("Now going to subscribe to the mono")
log.info("subscribing to mono on main thread")
mono.subscribe {
log.info("mono.subscribe called with {}", it)
done.countDown()
}
log.info("subscription done")
thread(name = "my-thread") {
log.info("subscribing to mono on a different thread")
mono.subscribe {
log.info("mono.subscribe called with {}", it)
done.countDown()
}
log.info("subscription done")
}
// waiting for subscribers to receive value before ending the test
done.await()
}
Act 1: assemble
The first thing this example does is create a Mono<Int> and store it in the mono value (a Mono<T> is a special kind of publisher that completes successfully by emitting a single element, or completes with an error). This is done by
- First, creating a
Mono<Int>using thecreatestatic function. - Using the
mapoperator to obtain a second mono that will emit the value from the first one, multiplied by 2. - Using the
delayElementoperator to obtain a third mono that will emit the element after a 1000 millisecond delay. - Finally, using the
mapoperator again to create a final mono that will emit the value divided by 2.
The assemble act uses reactive operators (e.g. map, delayElement) to build a data processing pipeline, represented in the following figure.

Note that during this phase no data is being transformed or emitted, only the pipeline is being assembled. As an example, the call to the map method does not immediately perform a data transform. Instead, it just returns a new mono that will emit the transformed value sometime in the future. In other words, nothing happens until there is a subscription to the mono (at least for cold publishers, but that is the subject of another post).
Act 2: subscription
After the processing pipeline is built, then we can pass on to the second act: the subscription. In this phase, subscribers that want access the data emitted by the mono, call the subscribe method, passing in a callback function.
In our example, we perform the subscription on the main thread and on a newly created thread. The end goal is to illustrate that:
- The same mono can be subscribed multiple times.
- The subscription can perfectly happen on a different thread from the one where the mono was created.
The following log output shows some interesting results.
15:29:39.616 [ main] INFO - Creating the mono, i.e., the processing pipeline
15:29:39.692 [ main] INFO - Mono created, resting for a bit...
15:29:40.692 [ main] INFO - Now going to subscribe to the mono
15:29:40.693 [ main] INFO - subscribing to mono on main thread
15:29:40.700 [ main] INFO - Mono.create callback called, emitting value
15:29:40.701 [ main] INFO - map: multiplying value by 2
15:29:40.703 [ main] INFO - subscription done
15:29:40.705 [ my-thread] INFO - subscribing to mono on a different thread
15:29:40.707 [ my-thread] INFO - Mono.create callback called, emitting value
15:29:40.707 [ my-thread] INFO - map: multiplying value by 2
15:29:40.707 [ my-thread] INFO - subscription done
15:29:41.704 [parallel-1] INFO - map: dividing value by 2
15:29:41.707 [parallel-2] INFO - map: dividing value by 2
15:29:41.707 [parallel-1] INFO - mono.subscribe called with 42
15:29:41.708 [parallel-2] INFO - mono.subscribe called with 42- The callback function passed into the
Mono.createis only called when there is a subscription. In addition, it is called once per subscription, in the same thread where the subscription is performed and before the subscribe method even returns. - Since the callback immediately emits a value (
it.success(42)) when called, then the next processing phase in the pipeline (i.e. the one defined by the firstmap) is also immediately called (seemap: multiplying value by 2), also before thesubscribemethod returns.
Act 3: data flow
As we saw in the previous log, the flow of data through the pipeline is only started when there is a subscription. Namely, both the create callback and the first processing phase happened synchronously with the subscription (i.e. at the same time and in the same thread).
However, the second map processing phase (see map: dividing value by 2) and the subscription callback are performed on a different thread, after approximately one second. That happens because between the first and the second map there is a delayElement: the value is only emitted into the second map phase one second after being produced by the first map phase.
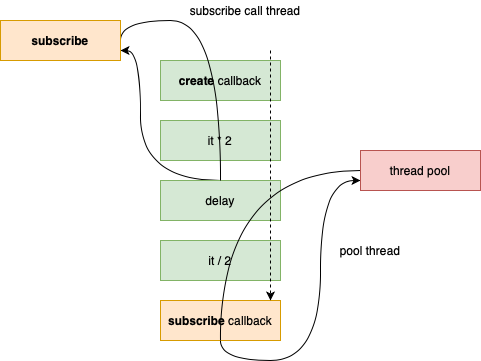
This is an example of an asynchronous processing phase. Since a fundamental characteristic of reactive streams is that there should be no blocking, the thread that performs the first map is released and the second map is performed on a thread managed by Reactor, only when the delay period elapses.
The flow of data through the pipeline starts when there is a subscription but it doesn’t end there. Namely, if there are asynchronous processing phases in the pipeline, the flow can pause (without blocking) and resume when some asynchronous event happens (e.g. a time period elapses, a message from a remote system is received). That is, the flow can be divided into multiple segments, with non-blocking pauses between them.
Summary
- There are at least three different moments (the acts) associated with reactive streams
- The pipeline assembly.
- The subscription.
- The data flow, through the pipeline.
- Nothing happens until there is a subscription.
- Data flow can happen partially or totally during the subscription.
- Data flow can be divided into multiple segments, with non-blocking pauses between them (e.g. time delay, waiting for external system event).
- On a cold publisher, there is a flow of data per each subscription. In the case of a mono, that flow will be comprised of a single element (at most).
The source code is available on the webflux-with-kotlin-by-example repository.
HTH